

1. iframe으로 이동하여 무한 스크롤하기
# iframe 안으로 들어가기
browser.switch_to.frame('searchIframe')
# iframe 안쪽을 한 번 클릭한다
browser.find_element(By.CSS_SELECTOR, 'div.Ryr1F').click()
# 로딩 전 리스트 개수 확인
lists = browser.find_elements(By.CSS_SELECTOR,'li.UEzoS')
before_scroll = len(lists)
# 무한 스크롤
while True:
# 스크롤을 맨 페이지 하단으로 내린다
browser.find_element(By.CSS_SELECTOR,'body').send_keys(Keys.END)
# 스크롤 사이 페이지 로딩 시간을 반드시 줘야 한다!!!!
time.sleep(1)
# 스크롤 후 로딩 된 리스트 개수 확인
lists = browser.find_elements(By.CSS_SELECTOR,'li.UEzoS')
after_scroll = len(lists)
# 로딩된 데이터 개수가 같다면 반복 멈춤
if after_scroll == before_scroll:
break
before_scroll = after_scroll
2. Selenium & BeautifulSoup 연동하기
# selenium으로 가져오면 느리다.
# selenium & BeautifulSoup 연동 방법
html = browser.page_source
soup = BeautifulSoup(html, 'html.parser')
lists = soup.select('li.UEzoS')
for li in lists:
# 광고가 아닌 가게만 가져온다
if len(li.select('svg.dPXjn')) == 0 :
# 별점이 있는 가게만 가져온다
if len(li.select('span.h69bs.a2RFq')) > 0 :
ratio = li.select_one('span.h69bs.a2RFq')
# 불필요한 span 삭제
span = ratio.select_one('span.place_blind')
span.decompose()
name = li.select_one('span.place_bluelink.TYaxT').text
try :
review = li.select_one('div.MVx6e > span.h69bs:nth-child(3)').text
review = review.replace("리뷰", '')
except :
review = "0"
ws.append([name, float(ratio.text), review])
time.sleep(0.3)
print(name, float(ratio.text), review)
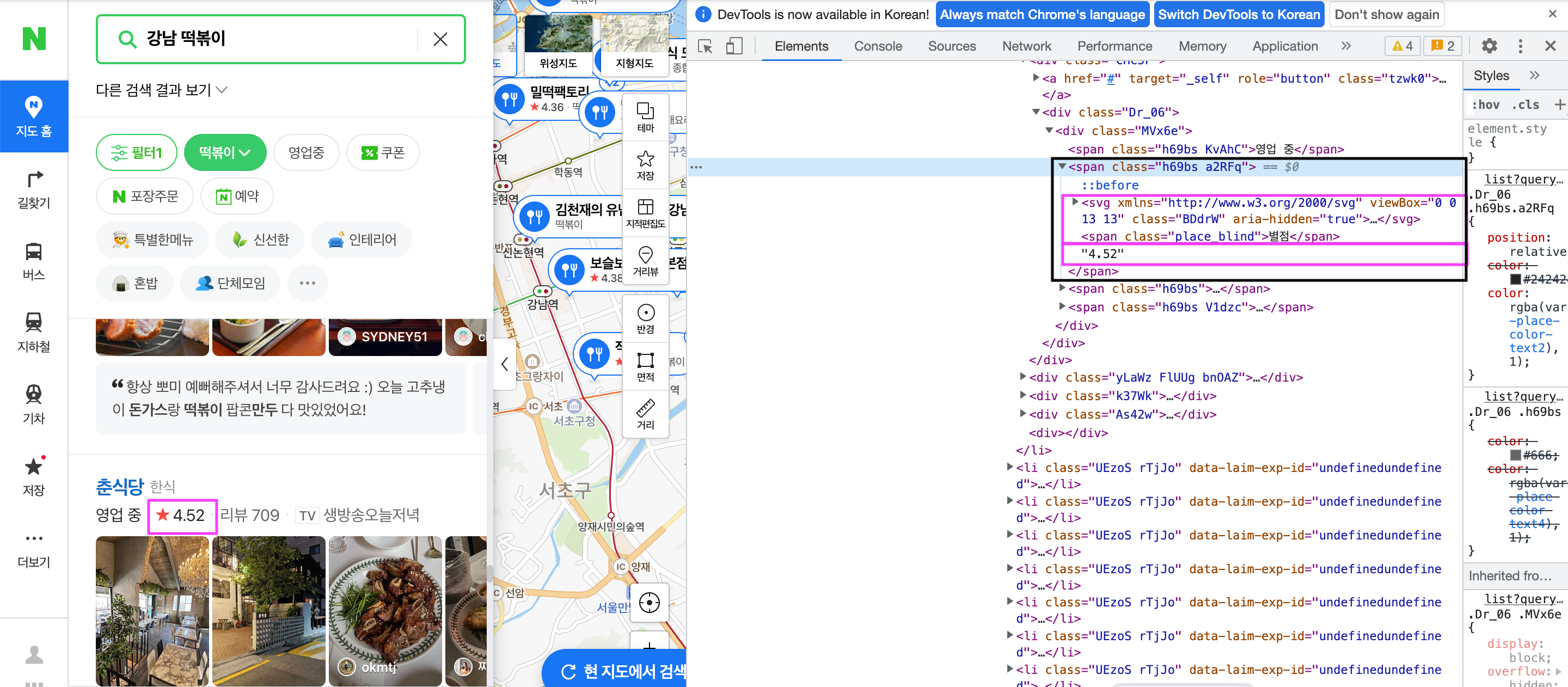
3. bs4를 이용한 웹페이지 크롤링 중 특정 태그 이하의 내용을 삭제하고 싶은 경우
전체 별점 span 영역에서 '별점'을 제외하고 가져올 수 있도록 decompose()를 활용하였다.
ratio = li.select_one('span.h69bs.a2RFq')
# 불필요한 span 삭제
span = ratio.select_one('span.place_blind')
span.decompose()'crawling' 카테고리의 다른 글
| 동적 html을 Selenium이 아닌 request로 크롤링하기 (0) | 2023.01.28 |
|---|---|
| Selenium & BeautifulSoup 연동 방법 / 유우키 영상 크롤링하기 (0) | 2023.01.27 |
| selenium으로 슬램덩크 이미지 크롤링하기 (0) | 2023.01.27 |
| request로 네이버 뉴스 본문/쿠팡 크롤링하기 (0) | 2023.01.26 |